Model regresi linier sederhana dalam populasi adalah
\[ y_i=\beta_0+\beta_1x_i+\epsilon_i \]
dengan,
\(y_i\) adalah variabel dependen untuk individu ke-\(i\)
\(x_i\) adalah variabel independen untuk individu ke-\(i\)
\(\beta_0\) adalah intersep model
\(\beta_1\) adalah slope model.
Asumsi Regresi Linier
Linieritas
Model regresi mengasumsikan hubungan antara \(y_i\) dan \(x_i\) yang bersifat linier, jika hubungannya tidak linier maka persamaan garis tidak akan linier memberikan kecocokan yang memadai dan model yang dihasilkan tidak tepat.
Homogenitas Variansi
Varians dalam residu diasumsikan konstan berapa pun nilai \(x_i\)nya. Asumsi ini biasanya juga disebut homoskedastisitas dan merupakan generalisasi dari homogenitas variansi galat pada Anova.
Normalitas
Asumsi ketiga adalah galat dalam populasi diasumsikan berdistribusi normal.
Diasumsikan bahwa variabel bebas \(x\) diukur tanpa kesalahan dan tidak berhubungan dengan istilah kesalahan model.
Independen
Residual antara dua individu dalam populasi diasumsikan independen satu sama lain. Faktor-faktor yang tidak terukur mempengaruhi \(y\) tidak berhubungan antara satu individu dengan individu yang lain. Asumsi inilah yang secara langsung diatasi dengan menggunakan pemodelan multilevel.
Keterbatasan Model Linier: Data Nested
Model regresi linier biasanya digunakan pada data tingkat individu yang diperoleh dari random sampling.
Dalam beberapa kasus yang menggunakan data nested, data dengan struktur bertingkat, diperlukan pengukuran bobot sampel untuk mengatasi oversampling dari sub-grup individu.
Keraguan peneliti dalam mengaplikasikan model linier, yang merupakan teknik level tunggal, pada data nested membuat peneliti mengembangkan multilevel model.
Penggunaan model regresi linier pada data multilevel akan melanggar salah satu asumsi regresi linier, yakni residual independen.
Sebagai contoh nilai ujian dari beberapa sampel pelajar yang berasal dari beberapa sekolah, mudah diasumsikan jika pelajar yang berasal dari sekolah sama akan memiliki nilai yang berkorelasi tinggi satu sama lain dibandingkan dengan pelajar dari sekolah lain. Korelasi sekolah yang sama dapat dikaitkan dengan guru yang sama, kurikulum yang sama, dan lain-lain.
Korelasi dalam sekolah akan memberikan estimasi standar error yang tidak sesuai untuk parameter model, sehingga menyebabkan error statistik inferensi, seperti p-value lebih kecil daripada yang seharusnya dan menolak hipotesis nol atas error tipe I, mengenai parameter.
Uji statistik untuk hipotesis nol tidak adanya hubungan antara variabel independen dan dependen adalah koefisien regresi dibagi standar error. Standar error yang underestimated menyebabkan overestimate uji statistik, sehingga signifikansi statistik parameter menjadi lebih tinggi daripada yang seharusnya. Underestimate standar error akan terjadi kecuali \(\tau^2 = 0\).
Selain underestimate standar error, permasalahan lain yang terjadi ketika mengabaikan data berstruktur multilevel adalah hilangnya informasi mengenai hubungan di setiap level data.
Data nilai ujian terdiri dari pelajar (level 1) yang nested dalam sekolah (level 2). Jika data sekolah diabaikan maka variabel-variabel penting mengenai sekolah seperti performa penguji juga akan terabaikan.
Estimasi Model Regresi dengan Ordinary Least Square (OLS)
Ordinary Least Square (OLS) atau metode kuadrat terkecil merupakan salah satu metode yang paling sering digunakan untuk memperoleh estimasi parameter model regresi (\(b_0\) dan \(b_1\)). Tujuan dari OLS adalah untuk meminimalkan galat yaitu jumlah selisih kuadrat antara nilai \(y\) yang diamati dan nilai \(y\) yang diprediksi model pada seluruh sampel. Galat ditulis sebagai
\[
e_i=y_i-\hat{y}_i
\]
Oleh karena itu metode OLS digunakan untuk meminimalkan
\(r\) adalah koefisien korelasi Pearson antara \(x\) dan \(y\),
\(s_y\) adalah standar deviasi sampel dari \(y\)
\(s_x\) adalah standar deviasi sampel dari \(x\)
\(\bar y\) adalah rata-rata sampel \(y\)
\(\bar x\) adalah rata-rata sampel \(x\)
Illustration
library(tidyverse)
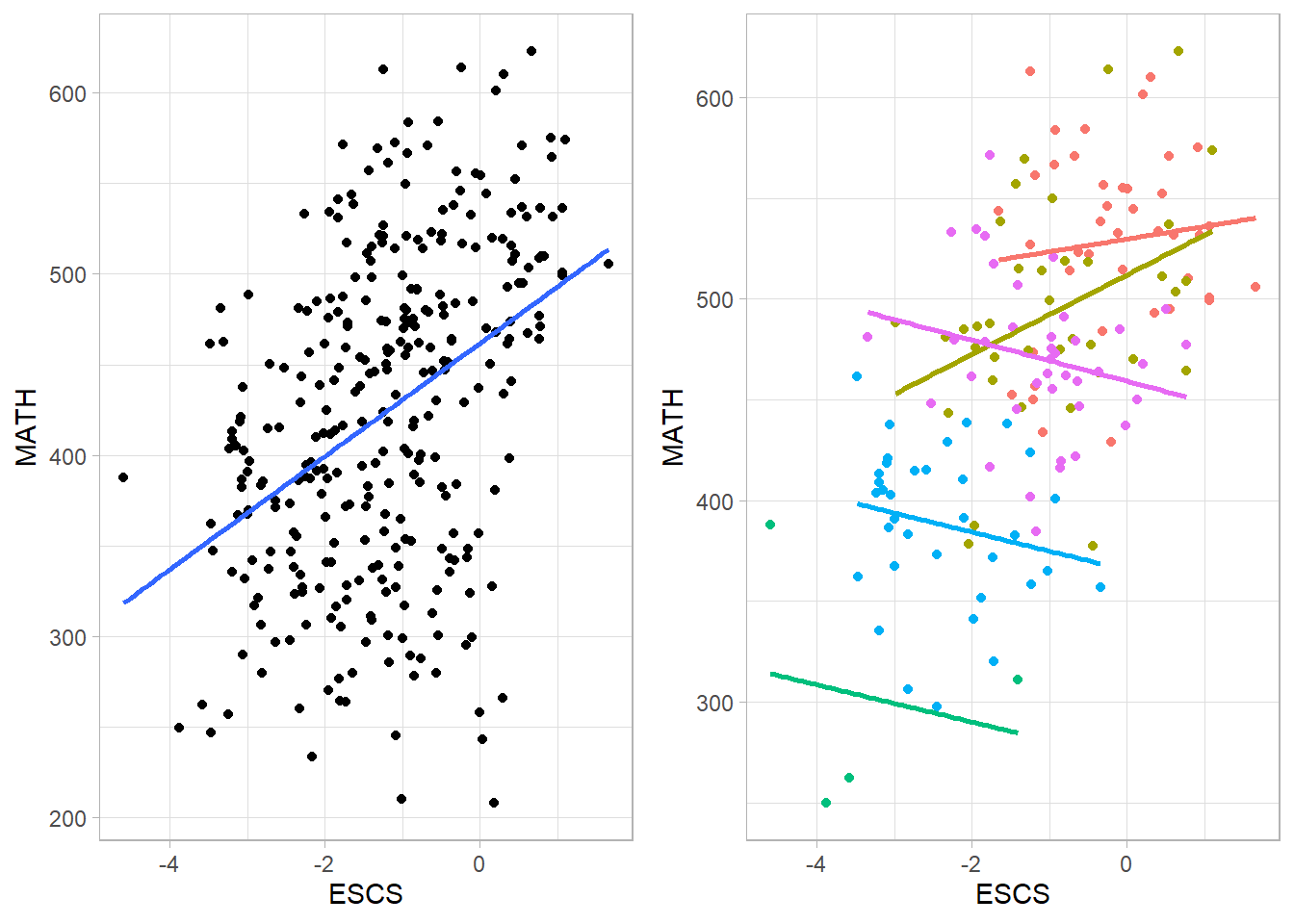
Peneliti akan meneliti seberapa besar hubungan sosial dan kesehatan dapat memprediksi kebahagiaan.
Penelitian ini melibatkan 72,000 responden dan peneliti akan menggunakan model linear.
Hasil penelitian menunjukkan bahwa hubungan sosial dan kesehatan memprediksi kebahagiaan secara signifikan.
Apa itu prediksi?
Ide dasar prediksi adalah menggunakan data yang sudah terkumpul mengenai variabel X dan Y dan melakukan kalkulasi tentang bagaimana X dapat memprediksi Y.
Contoh
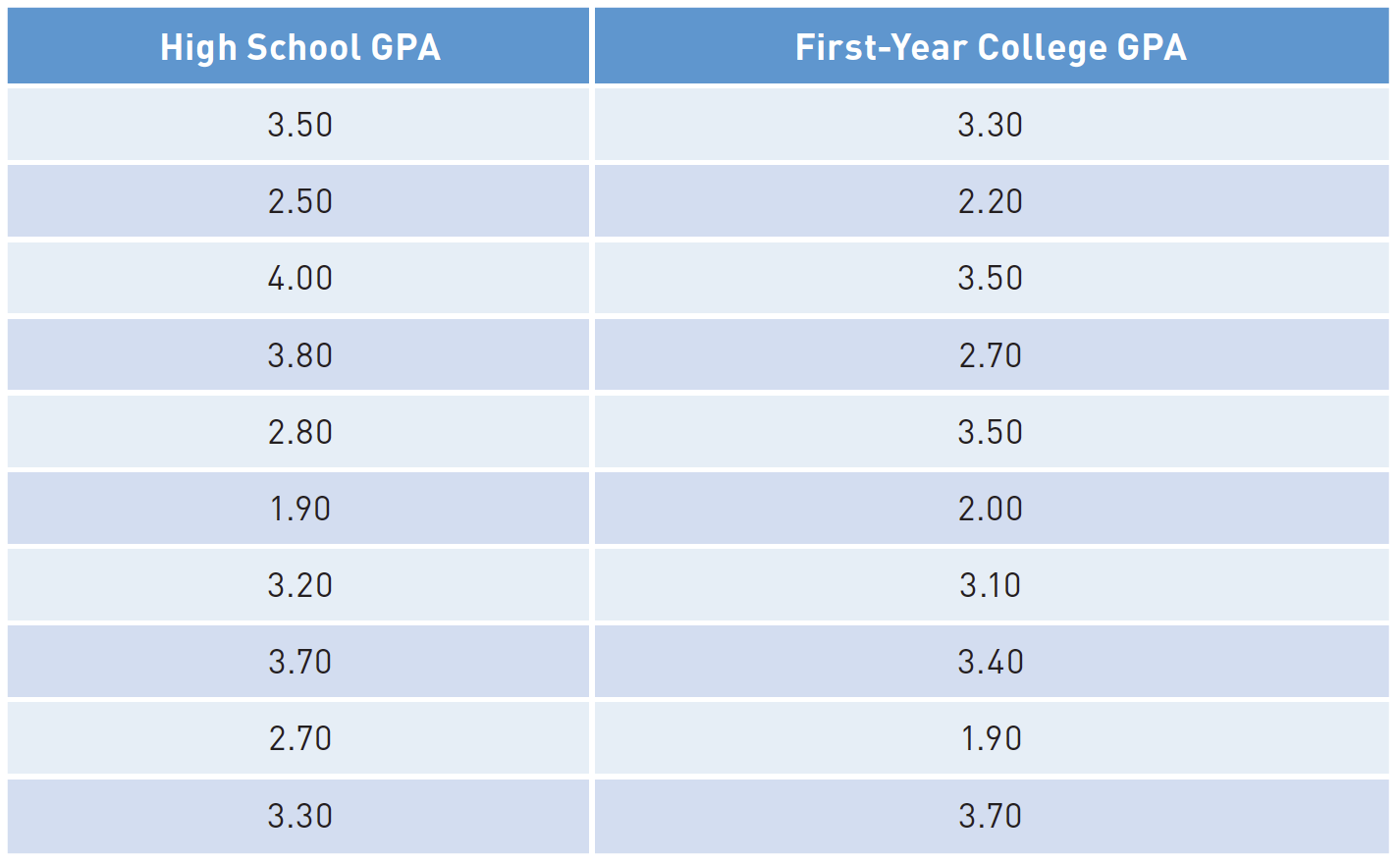
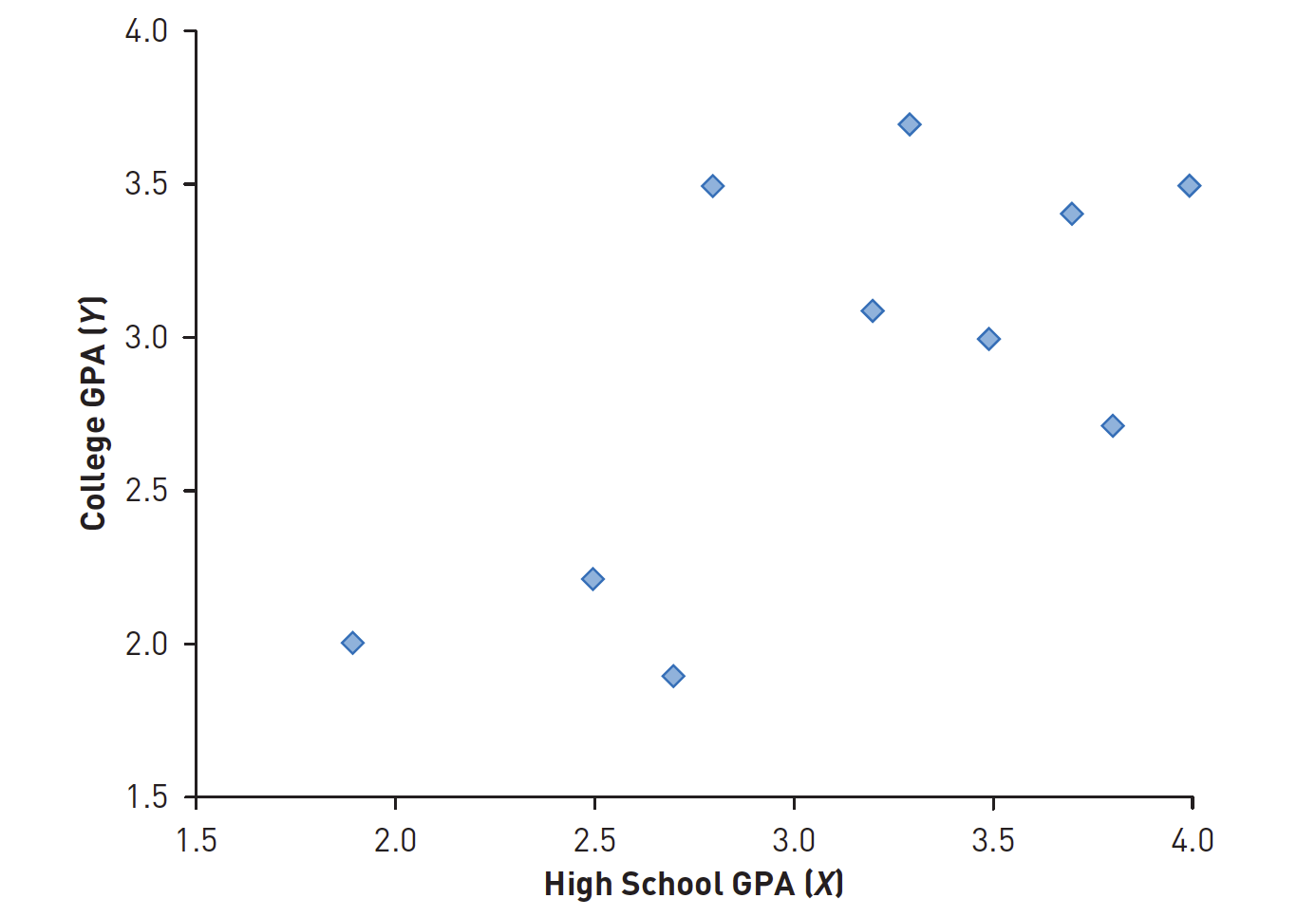
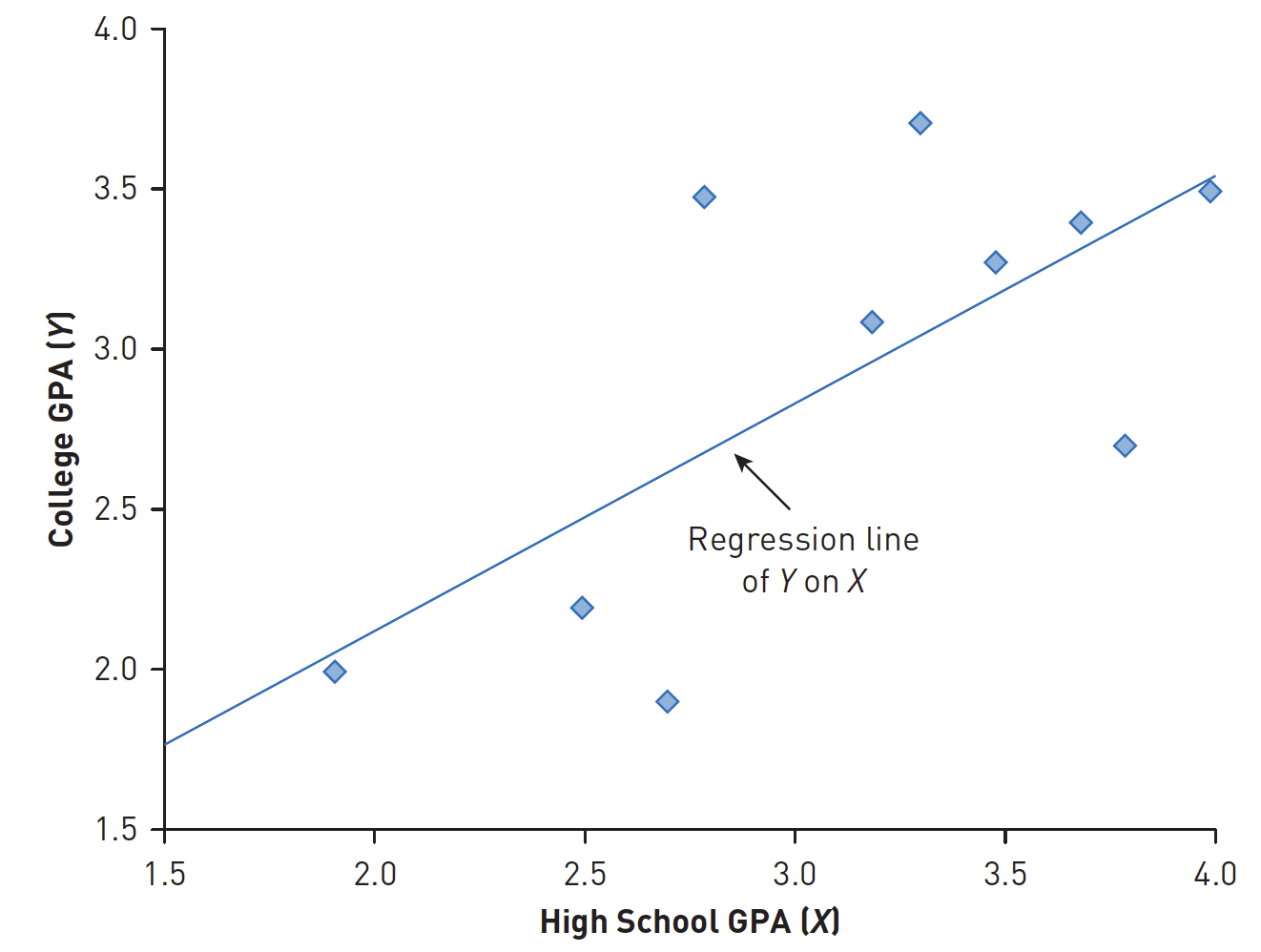
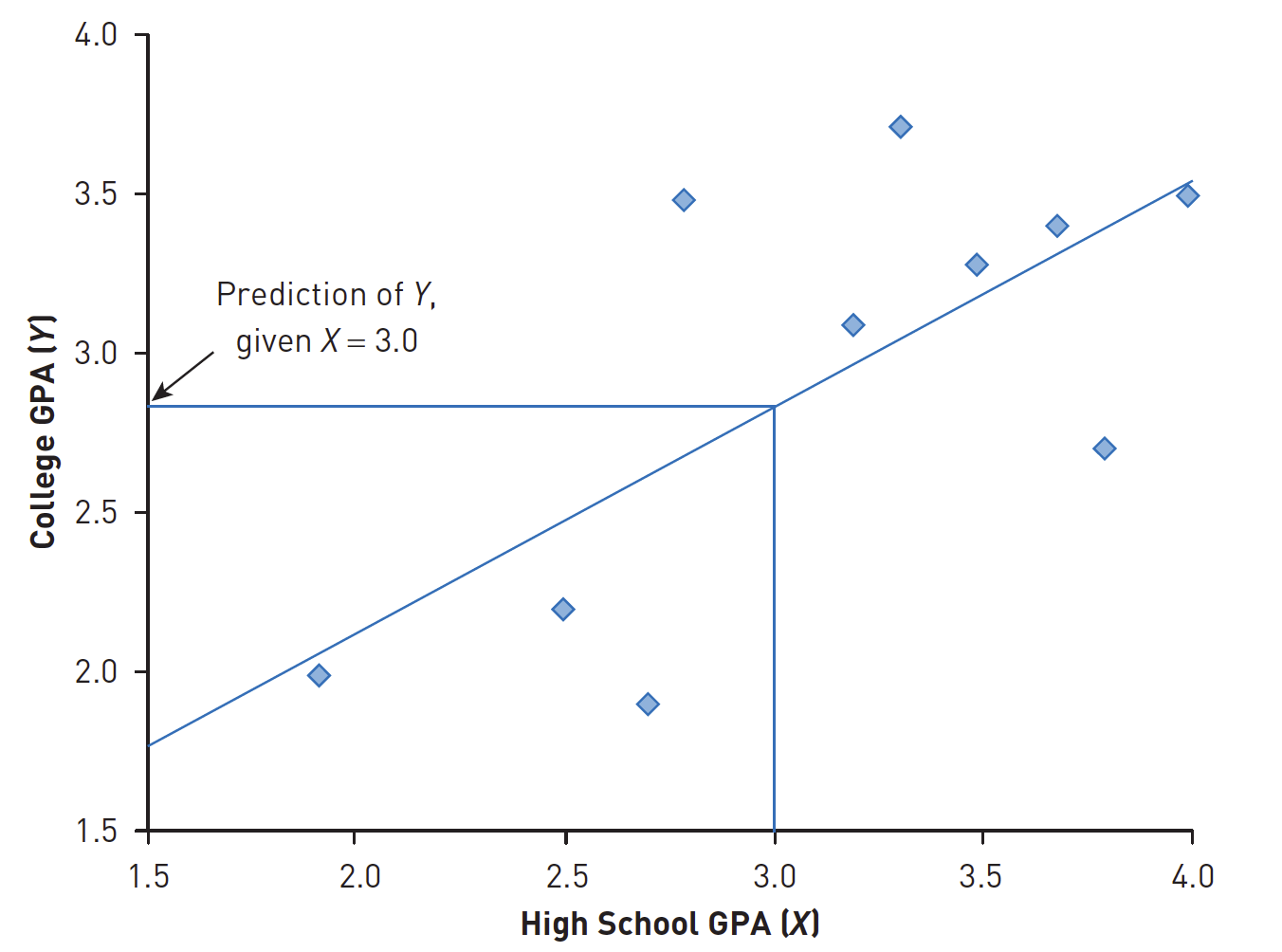
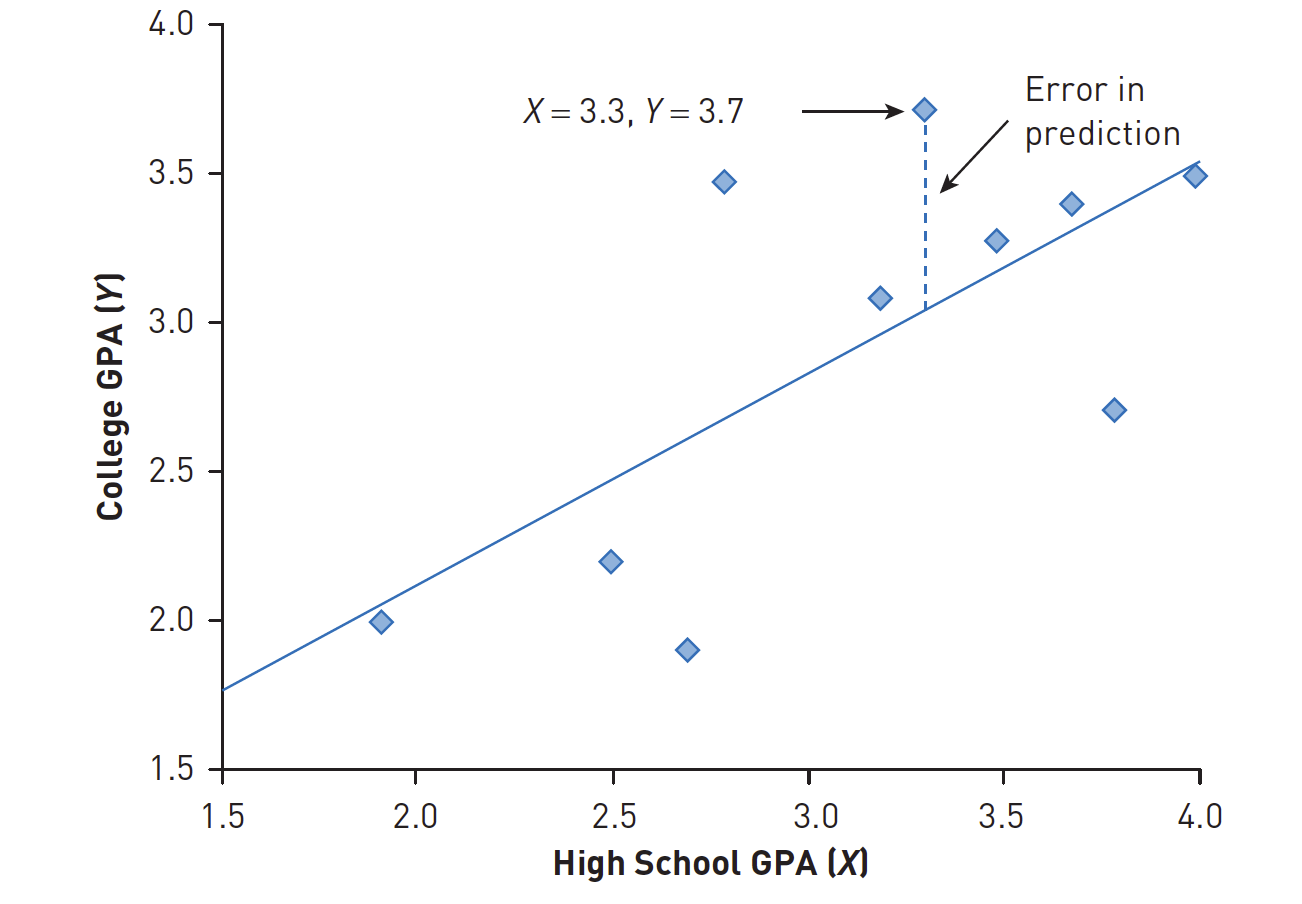
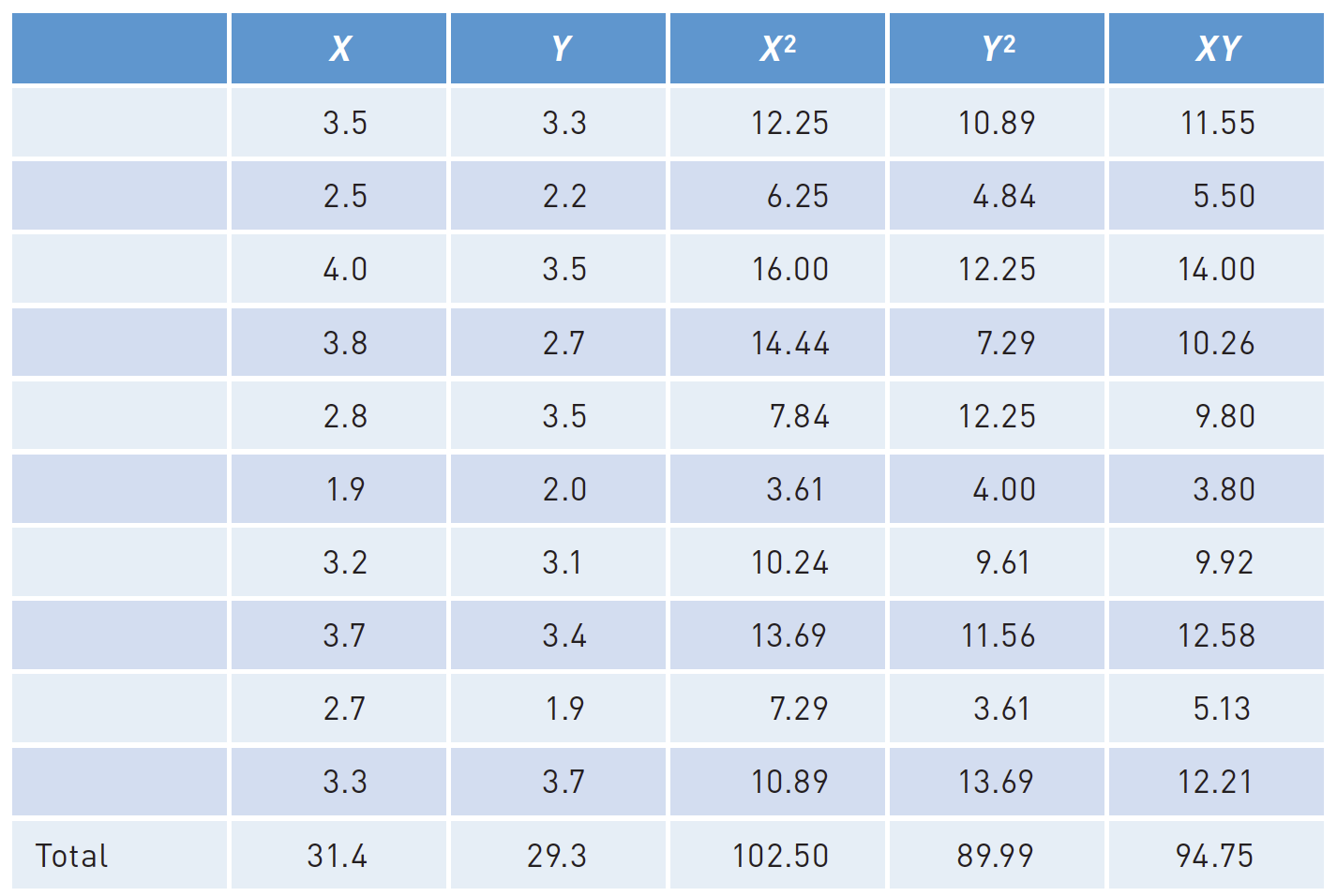
Seorang peneliti mengumpulkan data tentang total Indeks Prestasi Kumulatif (IPK) sekolah menengah atas dan IPK universitas tahun pertama untuk 400 siswa di tahun pertama mereka di universitas negeri.
Dia menghitung korelasi antara dua variabel. Kemudian, dia menggunakan teknik yang akan Anda pelajari nanti di bab ini untuk mengambil satu set IPK sekolah menengah baru dan (mengetahui hubungan antara IPK sekolah menengah atas dan IPK perguruan tinggi tahun pertama dari kumpulan siswa sebelumnya) memprediksi apa yang pertama- tahun IPK harus untuk sampel baru 400 siswa.
The logic of prediction
Prediksi adalah perhitungan hasil masa depan berdasarkan pengetahuan yang sekarang.
Ketika kita ingin memprediksi satu variabel dari yang lain, pertama-tama kita perlu menghitung korelasi antara kedua variabel tersebut.
Data
Plot
Regression line
Predicting
Error in predictiong
Basic formula of regression
\[
y=bX+a
\]
y is the predicted score of Y based on a known value of X,
b is the slope of the line,
X is the score being used as the predictor, and
a is the point at which the line crosses the y-axis.
Detailed formula
\[
b = \frac{{\Sigma{XY}}-(\Sigma{X}\Sigma{Y}/n)}{\Sigma{X^2}-[(\Sigma{X})^2)/n]}
\]