Tabel distribusi frekuensi sederhana dicontohkan seperti pada seperti Table 1 dan Table 2.
Distribusi Frekuensi Variabel Nominal
Distribusi frekuensi variabel nominal dicontohkan seperti pada Table 1
wvs |>count(jenis_kelamin) |>gt() |>cols_label(jenis_kelamin ="Jenis kelamin",n ="Frekuensi") |>opt_stylize(style =6, color ="blue") |>tab_source_note(source_note ="Sumber: Data WVS 7")
Table 1: Frekuensi responden berdasarkan jenis kelamin
Jenis kelamin
Frekuensi
Laki-laki
1314
Perempuan
1569
Sumber: Data WVS 7
Distribusi Frekuensi Variabel Ordinal
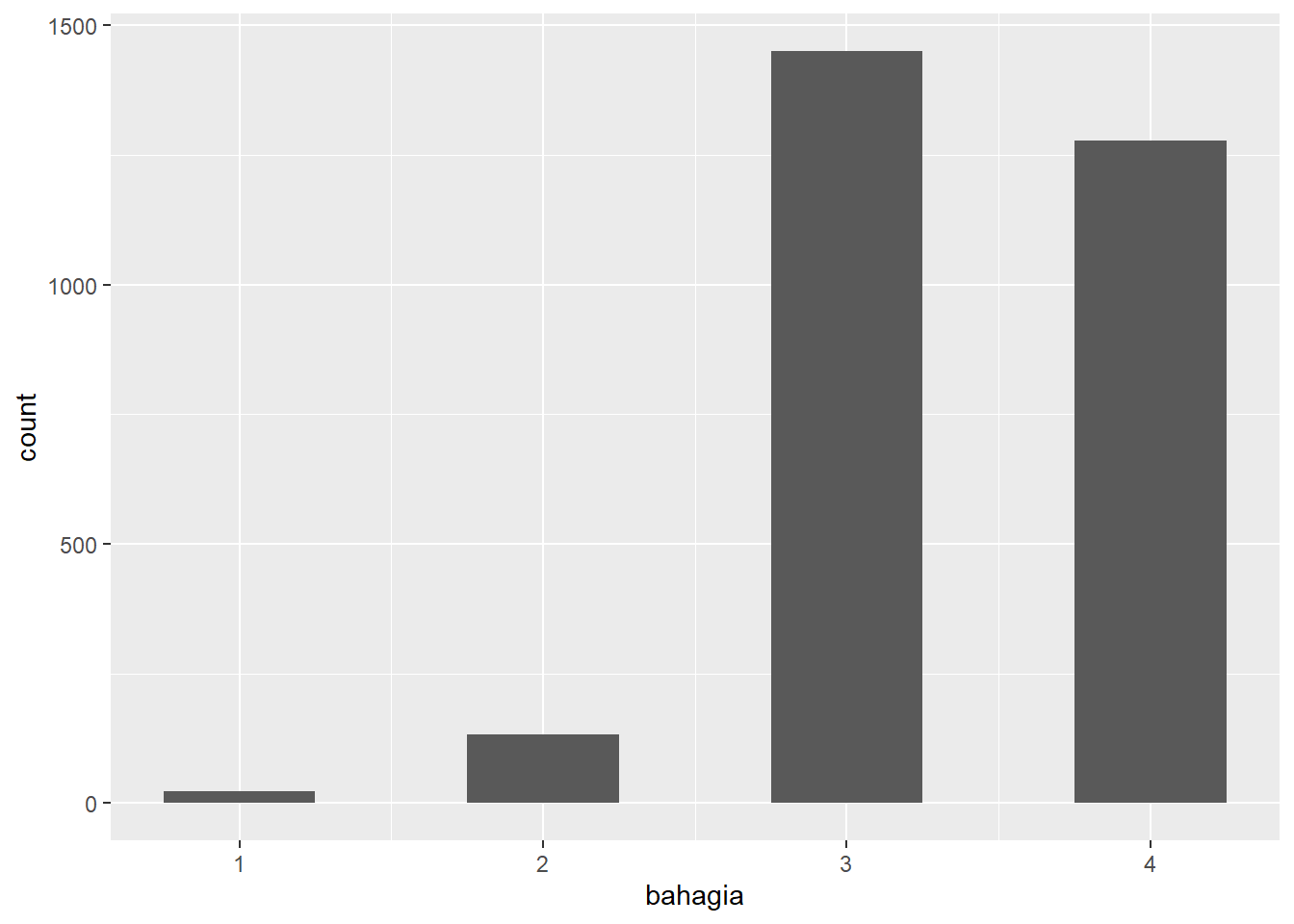
wvs |>count(bahagia_recode) |>mutate(bahagia_recode =factor(bahagia_recode, c("Tidak bahagia sama sekali","Tidak begitu bahagia","Cukup bahagia","Sangat bahagia"))) |>arrange(desc(bahagia_recode)) |>gt() |>cols_label(n ="Frekuensi",bahagia_recode ="Kebahagiaan") |>opt_stylize(style =6, color ="blue") |>tab_source_note(source_note ="Sumber: Data WVS 7") %>%cols_align(align ="left",columns = bahagia_recode)
Table 2: Frekuensi responden berdasarkan kebahagiaan
Kebahagiaan
Frekuensi
Sangat bahagia
1277
Cukup bahagia
1450
Tidak begitu bahagia
133
Tidak bahagia sama sekali
23
Sumber: Data WVS 7
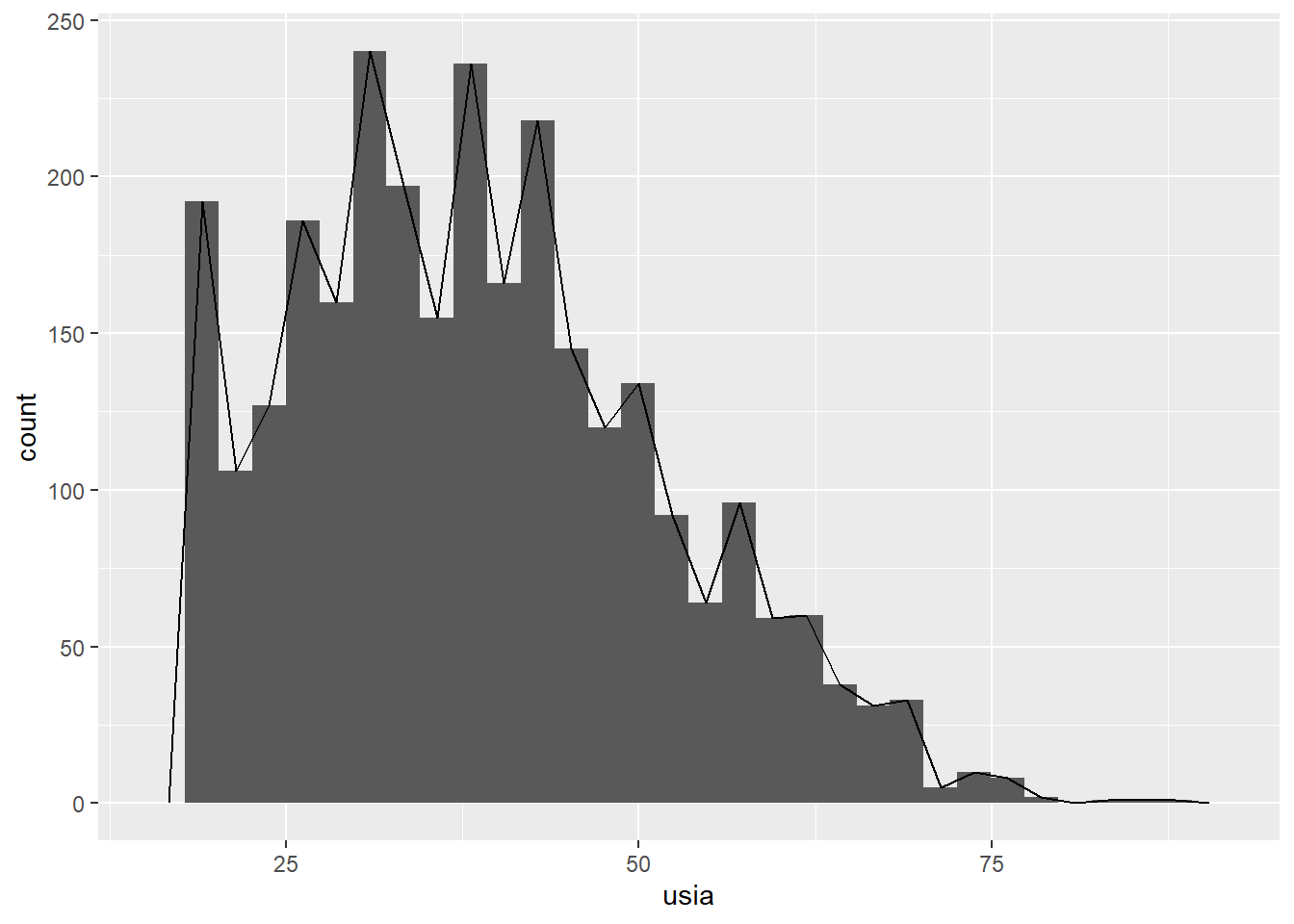
Distribusi Frekuensi Variabel Interval
wvs |>mutate(`Usia`=case_when(usia <=30~"18-30", usia <=50~"31-50", usia <=70~"51-70", usia >70~">70")) |>count(`Usia`) |>gt() |>cols_label(n ="Frekuensi") |>opt_stylize(style =6, color ="blue") |>tab_source_note(source_note ="Sumber: Data WVS 7")
Table 3: Frekuensi responden berdasarkan interval usia
Usia
Frekuensi
18-30
859
31-50
1492
51-70
504
>70
28
Sumber: Data WVS 7
Proporsi dan Persentase
Proporsi
Proporsi frekuensi (\(p\)) diperoleh dengan membagi frekuensi setiap kategori (\(f\)) dengan total pengamatan (\(N\)):
\[
p = \frac{f} {N}
\]
Frekuensi responden yang berjenis kelamin laki-laki adalah
\[ p_{laki-laki} = \frac {1314} {2883}=0.456 \]
Sedangkan frekuensi responden yang berjenis kelamin perempuan adalah
\[ p_{perempuan} = \frac {1569} {2883}=0.544 \]
wvs |>count(jenis_kelamin) |>mutate(Proporsi =round(n /sum(n), 2)) |>gt() |>cols_label(jenis_kelamin ="Jenis kelamin",n ="Frekuensi") |>opt_stylize(style =6, color ="blue") |>tab_source_note(source_note ="Sumber: Data WVS 7")
Table 4: Proporsi responden berdasarkan jenis kelamin
Jenis kelamin
Frekuensi
Proporsi
Laki-laki
1314
0.46
Perempuan
1569
0.54
Sumber: Data WVS 7
Persentase
Proporsi frekuensi (\(p\)) diperoleh dengan membagi frekuensi setiap kategori (\(f\)) dengan total pengamatan (\(N\)) lalu dikalikan \(100\). Dalam laporan statistik, kebanyakan frekuensi disajikan dalam bnetuk persentase, bukan proporsi. Persentase mengekspresikan ukuran frekuensi seolah-olah ada 100 total pengamatan.
\[
persentase = \frac{f} {N} (100)
\]
Sehingga persentae responden yang berjenis kelamin perempuan adalah \[ persentase_{perempuan} = \frac {1569} {2883} (100) =54.4 \%\]
wvs |>count(jenis_kelamin) |>mutate(Proporsi = n /sum(n),Persen = Proporsi *100) |>mutate(Proporsi =round(Proporsi, 2),Persen =round(Persen, 1)) |>gt() |>cols_label(jenis_kelamin ="Jenis kelamin",n ="Frekuensi") |>opt_stylize(style =6, color ="blue") |>tab_source_note(source_note ="Sumber: Data WVS 7")
Table 5: Persentase responden berdasarkan jenis kelamin
Jenis kelamin
Frekuensi
Proporsi
Persen
Laki-laki
1314
0.46
45.6
Perempuan
1569
0.54
54.4
Sumber: Data WVS 7
Persentase Kumulatif
Table 6: Persentase kumulatif responden berdasarkan jenis kelamin
Rates menunjukkan prevalensi hasil atau peristiwa yang menarik perhatian pada populasi tertentu. Rates menunjukkan tentang frekuensi suatu kejadian relatif terhadap berapa kali peristiwa tersebut terjadi pada suatu kelompok tertentu.
\[
Rate = \frac {f_{kejadian \, aktual}} {f_{kemungkinan\,kejadian}}
\] Contoh sederhana adalah menghitung tingkat perceraian. Bagaimana kita tahu berapa banyak perceraian yang mungkin terjadi dalam periode waktu tertentu? Kita bisa menggunakan jumlah pernikahan yang terjadi dalam tahun tertentu atau jumlah semua pernikahan yang terjadi pada suatu populasi sebagai denominator. Rates Perceraian adalah jumlah perceraian yang terjadi dalam satu tahun dibagi dengan jumlah pernikahan yang terjadi pada tahun yang sama atau jumlah semua pernikahan yang terjadi pada suatu populasi.
Publikasi Badan Pusat Statistik (BPS) tahun 2015 menunjukkan angka perceraian di Indonesia di tahun 2016 sebanyak \(365,633\) dan angka pernikahan di tahun yang sama sebanyak \(1,837,185\), sehingga rates perceraian di Indonesia pada tahun 2016 adalah \(0.199\) atau \(19.9 \%\)
Rasio menunjukkan ukuran suatu kategori relatif terhadap kategori lainnya. Rasio diperoleh dari hasil pembagian frekuensi suatu kategori (\(f_1\)) dengan frekuensi kategori yang lain (\(f_2\)).