── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
here() starts at E:/Dropbox/Taw/Dropbox/project_august_24/kuliah-statistikaMenyiapkan Data dan Visualisasi
Membuat Data
Membuat data secara manual di R
contoh_data <- tibble(nama = c("a", "b", "c", "d", "e"),
jenis_kelamin = c("P", "L", "P", "P", "L"),
usia = c(20, 22, 21, 22, 22))
head(contoh_data)# A tibble: 5 × 3
nama jenis_kelamin usia
<chr> <chr> <dbl>
1 a P 20
2 b L 22
3 c P 21
4 d P 22
5 e L 22Membaca data
Package yang digunakan untuk membaca data adalah readr dan haven.
| Program dan format datanya | Fungsi yang digunakan |
|---|---|
| (.csv) | read_csv |
| (.txt) | read_delim |
| Microsoft Excel (.xlsx) | read_xlsx |
| SPSS (.sav) | read_sav |
| Stata (.dta) | read_dta |
| SAS (.sas) | read_sas |
data_wvs <- read_csv("../datasets/WVS_Cross-National_Wave_7_csv_v5_0.csv")Menyederhanakan Data
| Fungsi | Kegunaan |
|---|---|
| Select | Memilih variabel |
| Rename | Mengubah nama variabel |
| Filter | Menyaring data berdasarkan kriteria |
| Mutate | Menambah dan mengubah variabel |
| Recode | Mengubah respons variabel |
| Group_by | Mengelompokkan data untuk diterapkan fungsi |
Select
wvs <- data_wvs |>
select(B_COUNTRY_ALPHA, H_URBRURAL, Q260, Q262, Q273, Q275)
head(wvs)# A tibble: 6 × 6
B_COUNTRY_ALPHA H_URBRURAL Q260 Q262 Q273 Q275
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AND 1 2 60 1 3
2 AND 1 1 47 2 7
3 AND 1 1 48 4 7
4 AND 1 2 62 2 2
5 AND 1 1 49 2 2
6 AND 1 2 51 1 1Rename
wvs <- wvs |>
rename(negara = B_COUNTRY_ALPHA,
kota_desa = H_URBRURAL,
jenis_kelamin = Q260,
usia = Q262,
status_pernikahan = Q273,
pendidikan_terakhir = Q275)
head(wvs)# A tibble: 6 × 6
negara kota_desa jenis_kelamin usia status_pernikahan pendidikan_terakhir
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 AND 1 2 60 1 3
2 AND 1 1 47 2 7
3 AND 1 1 48 4 7
4 AND 1 2 62 2 2
5 AND 1 1 49 2 2
6 AND 1 2 51 1 1Filter
wvs <- wvs |>
filter(negara == "IDN")
head(wvs)# A tibble: 6 × 6
negara kota_desa jenis_kelamin usia status_pernikahan pendidikan_terakhir
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 IDN 2 1 20 6 3
2 IDN 2 2 35 1 1
3 IDN 2 1 21 6 3
4 IDN 2 1 35 1 1
5 IDN 2 2 21 1 3
6 IDN 2 1 23 6 3summary(wvs) negara kota_desa jenis_kelamin usia
Length:3200 Min. :-5.000 Min. :1.000 Min. :18.00
Class :character 1st Qu.: 1.000 1st Qu.:1.000 1st Qu.:30.00
Mode :character Median : 2.000 Median :2.000 Median :39.00
Mean : 1.732 Mean :1.548 Mean :40.03
3rd Qu.: 2.000 3rd Qu.:2.000 3rd Qu.:49.00
Max. : 2.000 Max. :2.000 Max. :87.00
status_pernikahan pendidikan_terakhir
Min. :1.000 Min. :-1.000
1st Qu.:1.000 1st Qu.: 1.000
Median :1.000 Median : 2.000
Mean :1.976 Mean : 2.256
3rd Qu.:1.000 3rd Qu.: 3.000
Max. :6.000 Max. : 8.000 wvs <- wvs |>
filter(kota_desa > 0) |>
filter(pendidikan_terakhir > 0)
summary(wvs) negara kota_desa jenis_kelamin usia
Length:2884 Min. :1.000 Min. :1.000 Min. :18.00
Class :character 1st Qu.:1.000 1st Qu.:1.000 1st Qu.:29.00
Mode :character Median :2.000 Median :2.000 Median :38.00
Mean :1.728 Mean :1.544 Mean :38.77
3rd Qu.:2.000 3rd Qu.:2.000 3rd Qu.:47.00
Max. :2.000 Max. :2.000 Max. :87.00
status_pernikahan pendidikan_terakhir
Min. :1.00 Min. :1.000
1st Qu.:1.00 1st Qu.:1.000
Median :1.00 Median :2.000
Mean :1.99 Mean :2.499
3rd Qu.:1.00 3rd Qu.:3.000
Max. :6.00 Max. :8.000 Mutate
wvs |>
mutate(contoh = usia + 100) |>
head()# A tibble: 6 × 7
negara kota_desa jenis_kelamin usia status_pernikahan pendidikan_terakhir
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 IDN 2 1 20 6 3
2 IDN 2 2 35 1 1
3 IDN 2 1 21 6 3
4 IDN 2 1 35 1 1
5 IDN 2 2 21 1 3
6 IDN 2 1 23 6 3
# ℹ 1 more variable: contoh <dbl>Recode
wvs <- wvs |>
mutate(kota_desa = recode(kota_desa,
`1` = "Perkotaan",
`2` = "Pedesaan"),
jenis_kelamin = recode(jenis_kelamin,
`1` = "Laki-laki",
`2` = "Perempuan"),
status_pernikahan = recode(status_pernikahan,
`1` = "Menikah",
`2` = "Tinggal bersama",
`3` = "Cerai hidup",
`4` = "Pisah",
`5` = "Cerai mati",
`6` = "Belum menikah"))
head(wvs)# A tibble: 6 × 6
negara kota_desa jenis_kelamin usia status_pernikahan pendidikan_terakhir
<chr> <chr> <chr> <dbl> <chr> <dbl>
1 IDN Pedesaan Laki-laki 20 Belum menikah 3
2 IDN Pedesaan Perempuan 35 Menikah 1
3 IDN Pedesaan Laki-laki 21 Belum menikah 3
4 IDN Pedesaan Laki-laki 35 Menikah 1
5 IDN Pedesaan Perempuan 21 Menikah 3
6 IDN Pedesaan Laki-laki 23 Belum menikah 3Group_by
wvs |>
group_by(jenis_kelamin) |>
mutate(usia_jenis_kelamin = mean(usia)) |>
head()# A tibble: 6 × 7
# Groups: jenis_kelamin [2]
negara kota_desa jenis_kelamin usia status_pernikahan pendidikan_terakhir
<chr> <chr> <chr> <dbl> <chr> <dbl>
1 IDN Pedesaan Laki-laki 20 Belum menikah 3
2 IDN Pedesaan Perempuan 35 Menikah 1
3 IDN Pedesaan Laki-laki 21 Belum menikah 3
4 IDN Pedesaan Laki-laki 35 Menikah 1
5 IDN Pedesaan Perempuan 21 Menikah 3
6 IDN Pedesaan Laki-laki 23 Belum menikah 3
# ℹ 1 more variable: usia_jenis_kelamin <dbl>Memvisualisasikan Data
Bar plot
ggplot(wvs, aes(x = status_pernikahan)) +
geom_bar()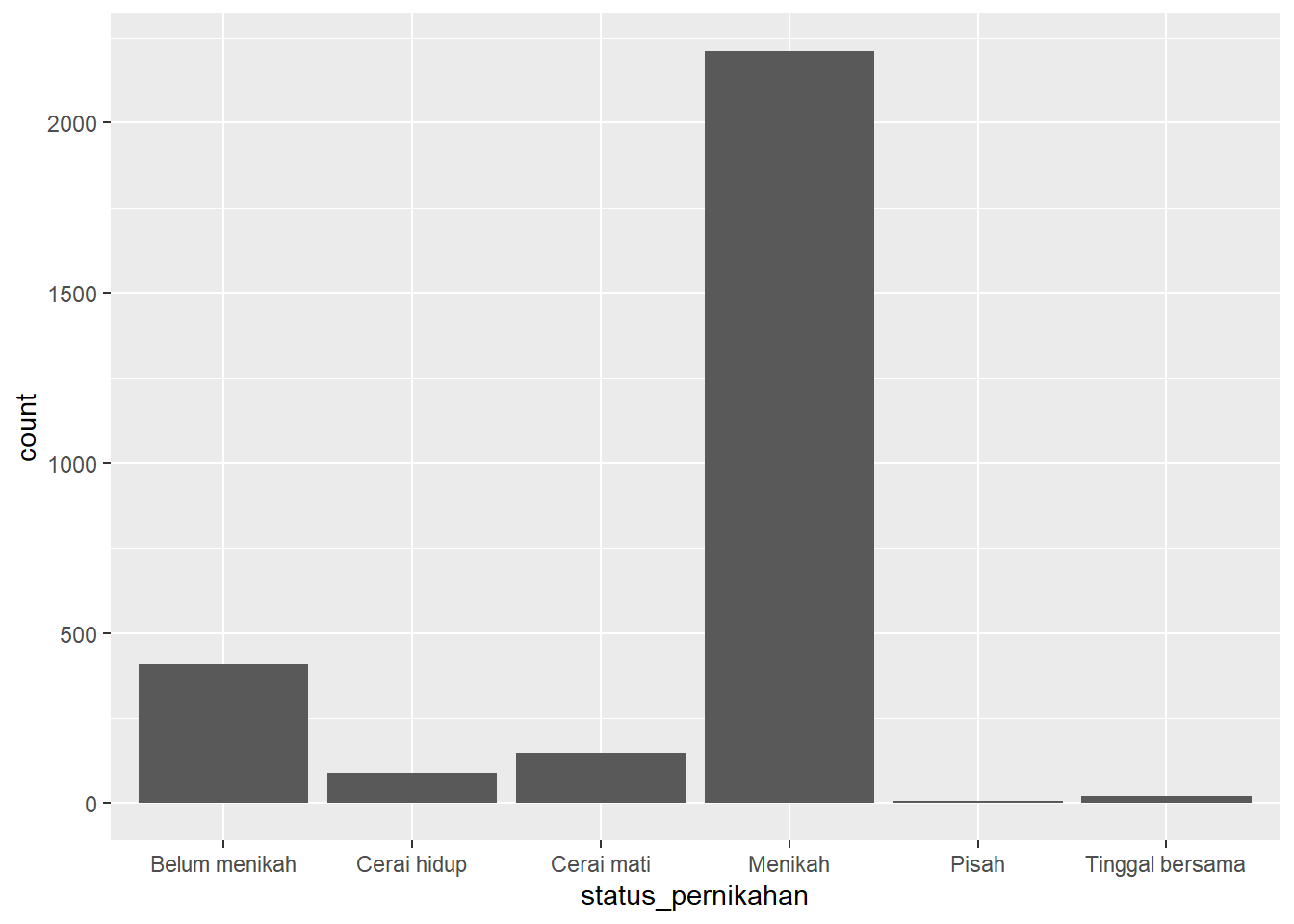
Box plot
ggplot(wvs, aes(x = kota_desa,
y = pendidikan_terakhir)) +
geom_boxplot()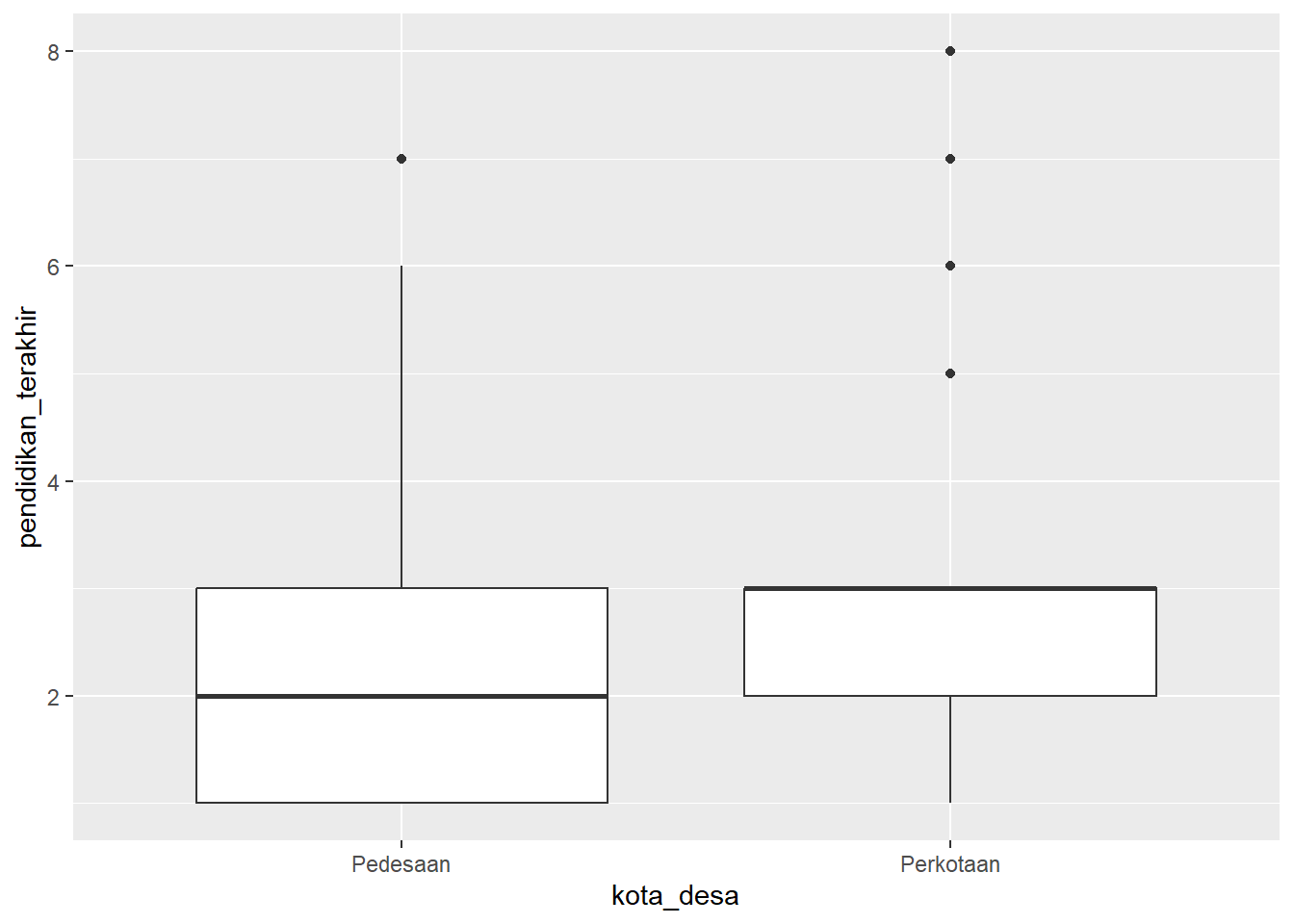
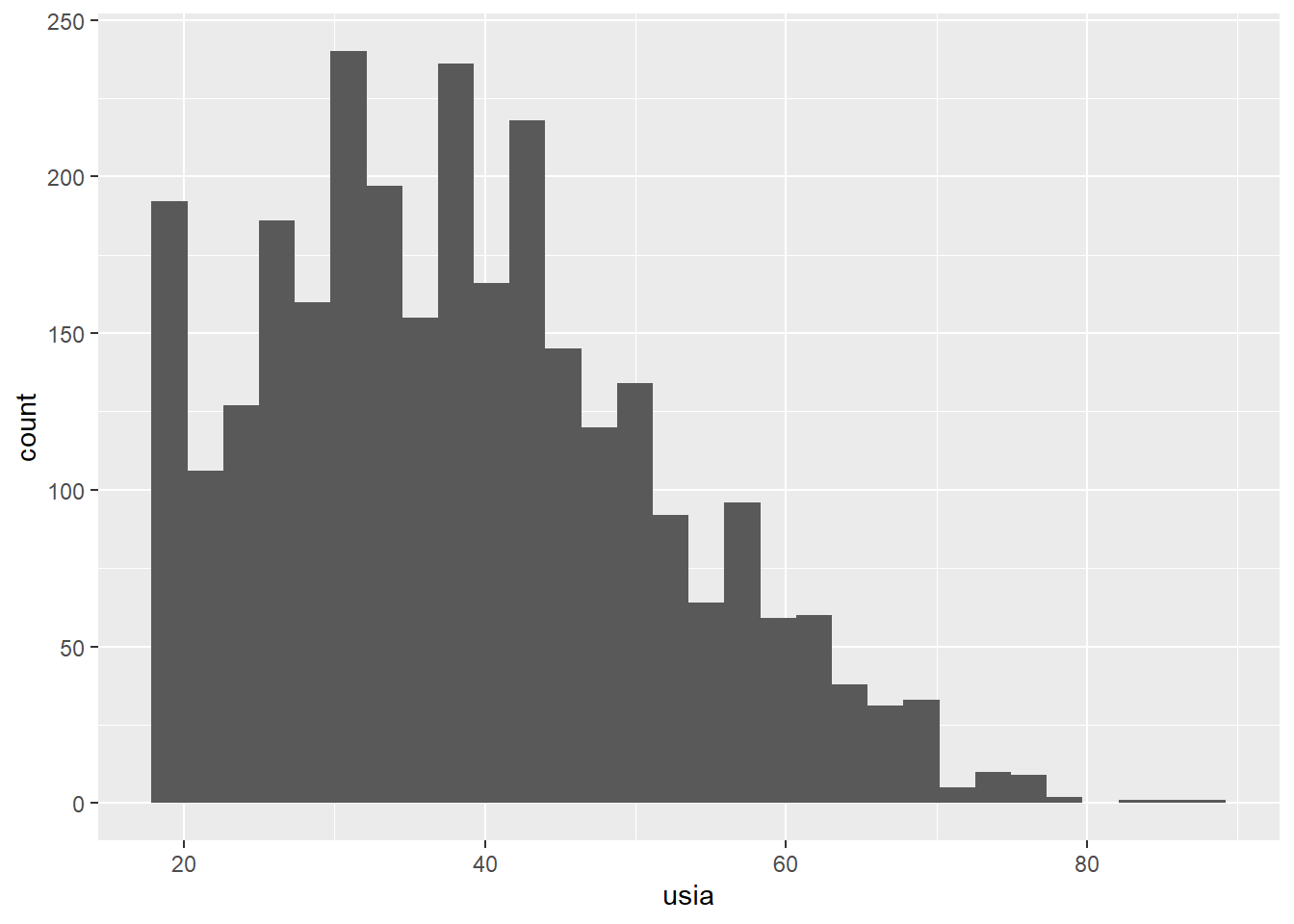
Histogram
ggplot(wvs, aes(x = usia)) +
geom_histogram(bins = 30)